Chat-GPT Prompt Engineering, les phrases magiques

Le prompt engineering : définition et enjeux
Le prompt engineering — ou l’art de formuler ses requêtes — est une compétence clé pour exploiter pleinement les grands modèles de langage (LLM) comme ChatGPT. Que vous soyez utilisateur aguerri, chercheur ou entrepreneur en IA, maîtriser cette technique vous permettra d’obtenir des résultats plus précis et pertinents.
Dans cet article, nous explorons ses fondements et partageons des méthodes concrètes pour optimiser vos échanges avec ces outils.
Pourquoi le prompt engineering est-il indispensable ?
Si vous avez déjà utilisé ChatGPT ou un autre LLM, vous avez sans doute constaté que les réponses ne correspondent pas toujours à vos attentes. Parfois, elles sont inexactes, voire totalement inventées.
Le défi ? Ces modèles, aussi sophistiqués soient-ils, reposent sur des réseaux de neurones « boîte noire » dont le fonctionnement interne reste opaque. Les utilisateurs doivent donc apprendre à affiner leurs requêtes pour en tirer le meilleur parti.
Chaque question ou instruction envoyée à un LLM est un prompt. Et un simple ajustement dans sa formulation peut radicalement transformer la qualité de la réponse.
Prenons un exemple concret : une question posée à ChatGPT qui génère une réponse erronée.

Quelle « phrase magique » ajouter à votre prompt pour obtenir la bonne réponse ? Découvrez ci-dessous comment y parvenir systématiquement grâce à quelques techniques de prompt engineering — et rassurez-vous, c’est plus simple qu’il n’y paraît.
Quelles techniques utiliser pour le prompt engineering ?
Le prompt engineering est une démarche dynamique qui consiste à orienter le modèle avec précision, soit en lui fournissant des exemples ponctuels (c’est le few-shot learning, abordé plus loin), soit en l’affinant via un jeu de données structuré de paires prompt-complétion (nous y reviendrons).
Si ChatGPT repose sur un modèle de génération de langage naturel et ne nécessite pas d’invites ultra-spécifiques, il gagne en pertinence dès qu’on lui offre un contexte riche et des exemples concrets. En somme : plus vous lui donnez d’informations, plus il cerne votre demande et vous livre une réponse ciblée.
Chez OpenAI, deux méthodes dominent pour exploiter le potentiel des grands modèles de langage (LLM) et améliorer la justesse des réponses : le few-shot learning et le fine-tuning.
L’apprentissage few-shot
Cette technique, parfois appelée few-shot learning, consiste à alimenter le modèle avec quelques exemples explicites pour le guider vers la production de réponses adaptées à une tâche donnée – classification, reconnaissance d’objets, etc. En règle générale, une dizaine d’exemples suffisent, mais ce nombre varie selon les cas. Lorsqu’un seul exemple est fourni, on parle alors d’apprentissage one-shot.
Avec les modèles OpenAI, cette approche peut être appliquée directement dans l’interface de ChatGPT ou de manière programmatique via l’API completion. Par exemple, pour classer des films par genre, il suffit d’intégrer quelques exemples dans votre message :
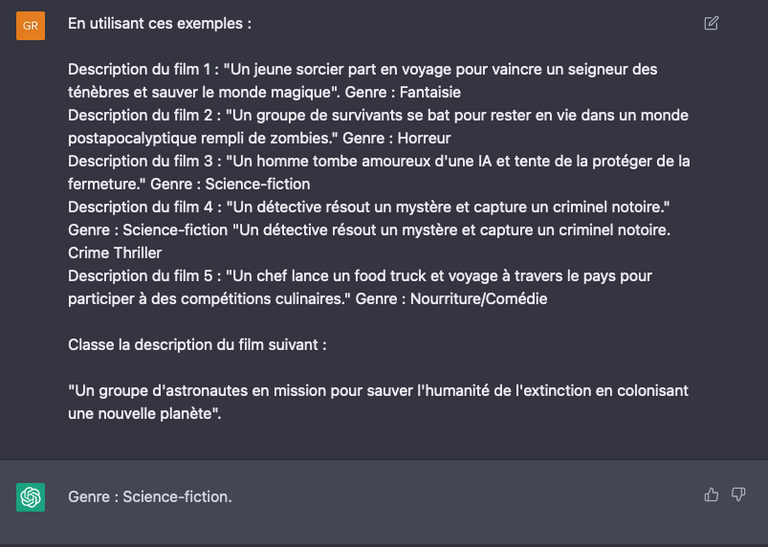
Exemple de few-shot learning pour aider un agent virtuel à catégoriser des films.
Grâce à ces exemples, ChatGPT identifiera correctement le genre du film décrit ainsi : « Un groupe d’astronautes en mission pour sauver l’humanité de l’extinction en colonisant une nouvelle planète » – soit de la science-fiction.
Bien sûr, saisir manuellement ces exemples pour une seule réponse n’aurait guère d’intérêt. Mais l’interface conversationnelle de ChatGPT permet de poursuivre l’échange jusqu’à épuisement des questions… ou du modèle !
L’interface conversationnelle permet d’enchaîner les requêtes.
Une méthode plus courante consiste à encoder ces exemples dans l’API completion d’OpenAI, ce qui ouvre la porte à des applications variées : service client automatisé convivial, sommelier virtuel associant vins et plats, etc.
Le modèle mental du « génie dans la pièce »
Jessica Shieh, stratège IA chez OpenAI, préconise une approche baptisée « génie dans la pièce ». L’idée ? Imaginer que le modèle (le génie) ne connaît de vous que ce que vous lui glissez sous la porte (le prompt).
Cette métaphore aide à cerner les limites et les besoins d’un LLM comme ChatGPT. Une fois ce cadre mental adopté, on comprend mieux comment obtenir des réponses précises.

Jessica Shieh, stratège IA chez OpenAI, illustre le concept du « génie dans une pièce ».
Par exemple, plus vous fournissez de contexte au « génie », plus ses réponses seront pertinentes. Trois bonnes pratiques émergent pour rédiger un prompt efficace :
- Définissez le problème à résoudre.
- Précisez le résultat attendu : format (« répondre en liste à puces »), ton (« répondre comme un professeur de maths patient »), etc.
- Apportez les connaissances spécifiques nécessaires à la tâche.
La chaîne de pensée zero-shot (CoT)
On parle aussi d’apprentissage zero-shot lorsque le modèle parvient à classer des concepts inédits. Par exemple, un modèle entraîné à reconnaître des chevaux pourrait identifier un zèbre comme un « cheval rayé », même sans l’avoir jamais vu.
L’objectif des méthodes x-shot (zero, one ou few) reste le même : apprendre à partir de peu de données pour généraliser à de nouveaux cas.
Dans ChatGPT, une astuce simple améliore notablement la précision : la zero-shot chain of thought (CoT). Il suffit d’ajouter « Pensons étape par étape » ou « Réfléchissons à voix haute » à la fin de votre prompt. Comme par magie, cette simple phrase aide le modèle à structurer sa réponse.
(Un exemple concret est présenté plus loin dans l’article.)
Le fine-tuning
Contrairement aux méthodes x-shot, qui se limitent à quelques exemples, le fine-tuning consiste à entraîner le modèle sur un jeu de données bien plus vaste. L’inconvénient ? Il nécessite des compétences en programmation.
Cet entraînement supplémentaire permet d’obtenir des performances supérieures et une meilleure précision sur des tâches spécifiques, comparé à un modèle brut ou entraîné sur peu d’exemples.

Les modèles OpenAI alimentent des applications pour de grandes entreprises.
Le fine-tuning sert généralement à adapter un modèle pré-entraîné (comme davinci d’OpenAI) à un domaine précis : marketing digital, droit des contrats, etc. Le modèle affiné peut ensuite être utilisé en interne ou intégré à une offre SaaS.

Ironclad utilise des modèles OpenAI pour automatiser la rédaction de contrats.
Une fois le modèle affiné, plus besoin de fournir des exemples dans le prompt. Cela réduit les coûts (chaque requête est facturée en jetons) et améliore l’efficacité en diminuant la latence. Autre avantage : le modèle reste privé, accessible uniquement via une clé API sécurisée.
Pour des résultats optimaux, il faut fournir un jeu d’exemples de qualité au format JSONL. Plus le volume est important, meilleures seront les performances. Un minimum de quelques centaines d’exemples est recommandé, idéalement validés par des experts du domaine.
Bonne nouvelle : OpenAI indique que les performances augmentent linéairement avec le nombre d’exemples. Pour tirer le meilleur parti du fine-tuning, visez donc le maximum (la limite se situe entre 80 et 100 Mo).
Revenons à la question où ChatGPT a trébuché
Reprenons cette question toute simple :
Quel est le 5ᵉ mot de la phrase « Tout vient à point à qui sait attendre » ?
Avec une approche zero-shot – celle qu’on a détaillée plus haut – et en glissant juste « pensons étape par étape » dans le prompt, voici ce qui se passe.

ChatGPT ne donne la bonne réponse qu’à une condition : qu’on lui souffle « pensons étape par étape ». Comme si, d’un coup de baguette, la solution tombait enfin juste.
(Petit conseil : si vous testez plusieurs variantes de prompts avant d’en arriver là, ouvrez un nouveau chat à chaque essai. Sinon, l’historique de la conversation risque de fausser les résultats.)
En résumé
Le prompt engineering est un champ en pleine effervescence, où les avancées s’enchaînent à un rythme soutenu. Ce qui pose problème aujourd’hui – comme les calculs complexes ou le raisonnement logique – pourrait bien être résolu demain.
Pour exploiter pleinement le potentiel d’un modèle comme ceux d’OpenAI, surtout si vous concevez des applications d’IA, que ce soit pour un usage interne ou en direction de vos clients, il faudra affiner votre approche. Deux pistes s’offrent à vous : l’apprentissage few-shot ou le fine-tuning, qui permettent de guider le modèle avec précision.
Ce que nous avons abordé ici ne représente qu’une infime partie de l’univers du prompt engineering. Si le sujet vous passionne, plongez-y sans hésiter.
Avec des modèles toujours plus performants et sophistiqués – certains estiment qu’ils pulvérisent la loi de Moore, passant d’un doublement de puissance tous les deux ans à un doublement tous les six mois –, une question se pose : arrivera-t-il un jour où ces systèmes seront si intelligents qu’ils devanceront nos besoins, rendant le prompt engineering superflu ?
L’avenir nous le dira.
Pour aller plus loin : agence IA en Guadeloupe · agents IA pour entreprise